Research
My main research interests are in the broad area of data science and big data, and its applications to cyber-physical systems and more recently to cybersecurity. In the past, as part of a multi-disciplinary team, I have initiated and led research in several projects related to sustainability and energy management of cyberphysical infrastructure such as smart buildings and data centers, including in energy disaggregation, meter (sensor) placement in buildings, anomaly detection, forecasting solar power generation and building energy consumption, mining temporal patterns in data center chillers, discovering thermal correlations and anomalies, visualization, and several other threads. Research Statement
Here are some selected research projects that I have initiated and led.

|
Building Energy Management:
Buildings are huge consumers of energy. In fact, in the U.S.,
buildings account for 40% of all energy use, and contribute about 8%
of the global carbon dioxide emissions. At the same time, they present
numerous opportunities for energy savings, e.g., it has been reported
that poorly maintained, degraded, and improperly controlled equipment
wastes 15-30% of energy in commercial buildings. How can data science
help in realizing some of these opportunities? This work addresses
multiple challenges to energy management in commercial buildings, including
1) meter placement, 2) anomaly detection, 3) demand forecasting, and
4) occupancy modeling.
[ACM TCPS 2017] [ACM BuildSys 2012] [KDD 2012] [ACM Buildsys 2011] |
|
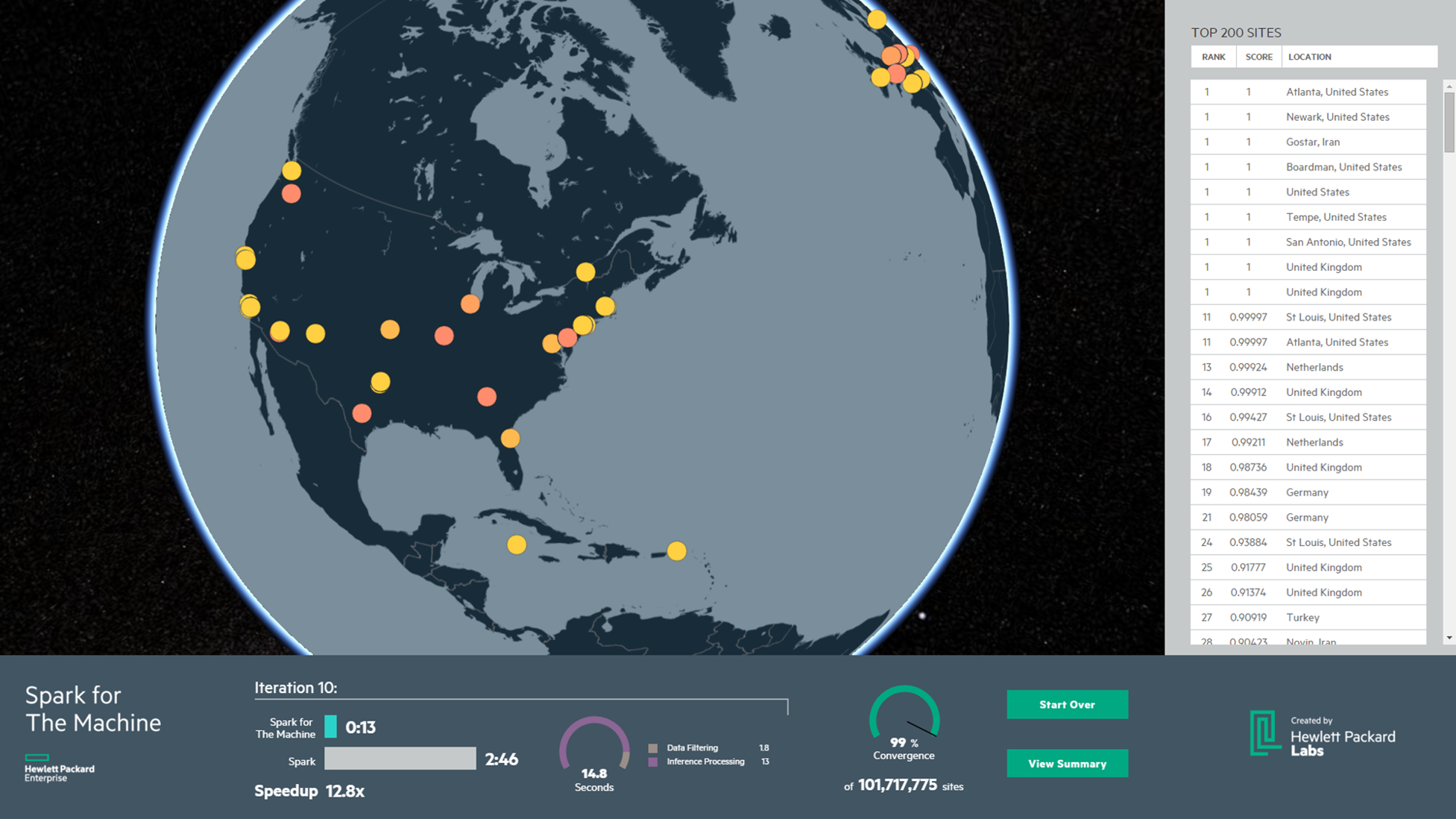
Large-scale graphical model inference:
We design and implement a scalable version of loopy
belief propagation (BP), a widely used algorithm for performing
inference on probabilistic graphical models, including in applications
related to fraud detection, malware detection, computer
vision, and customer retention. However, implementations of BP
on generic data processing platforms such as Apache Spark do
not scale well to very large graphical models containing billions
of vertices. To handle such large-scale graphs, we leverage a
number of strategies. Our implementation is based on Apache
Spark GraphX. We propose a novel graph partitioning strategy to
reduce both computation and communication overhead providing
a 2x speed-up. We use efficient memory management for storing
the graph and shared memory for high-speed communication.
To evaluate performance and demonstrate scalability of the
approach, we perform a range of experiments including using
real-world graphs with billions of vertices, where we achieve an
overall 10x speed-up over a vanilla Spark baseline. Further, we
apply our BP implementation to infer the probability of a website
being malicious by performing inference on a graphical model
derived from real, large-scale hyperlinked web-crawl data. We
have open sourced our implementation.
[IEEE BigData 2017] [Project Sandpiper]
|
|
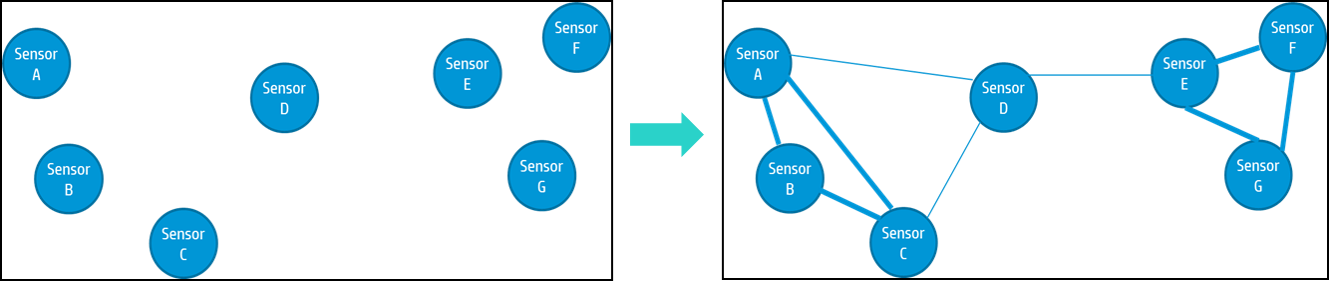
Robust, Large-scale Sensor Anomaly Detection:
Large-scale sensor networks are ubiquitous nowadays.
An important objective of deploying sensors is to detect
anomalies in the monitored system or infrastructure,
which allows remedial measures to be taken to prevent
failures, inefficiencies, and security breaches. Most existing
sensor anomaly detection methods are local, i.e.,
they do not capture the global dependency structure
of the sensors, nor do they perform well in the presence
of missing or erroneous data. In this work, we
propose an anomaly detection technique for large scale
sensor data that leverages relationships between sensors
to improve robustness even when data is missing or erroneous.
We develop a probabilistic graphical model-based
global outlier detection technique that represents
a sensor network as a pairwise Markov Random Field
and uses graphical model inference to detect anomalies.
We show our model is more robust than local models,
and detects anomalies with 90% accuracy even when
50% of sensors are erroneous. We also build a synthetic
graphical model generator that preserves statistical
properties of a real data set to test our outlier
detection technique at scale.
|
|
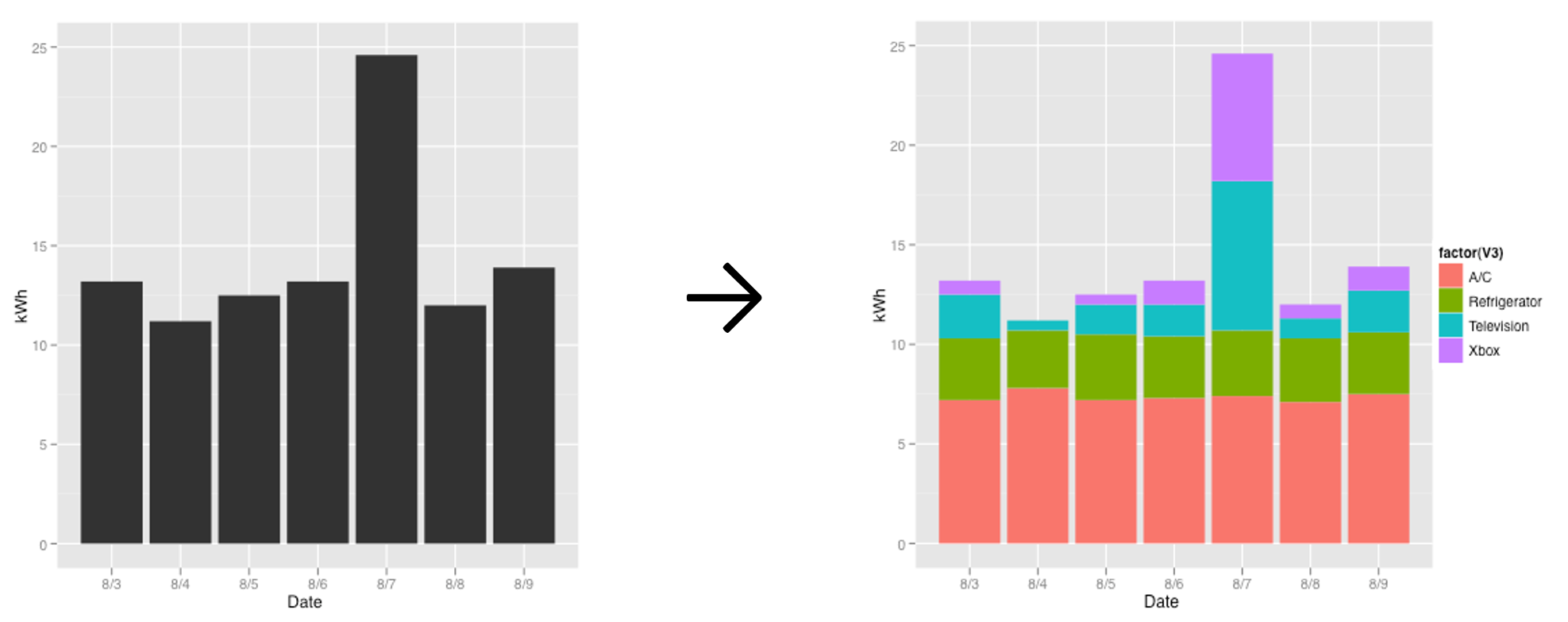
Energy Disaggregation: A problem faced by electricity consumers
is that utility bills, usually received at
the end of a month, provide only aggregate usage with no insight on which appliances/devices were the top
consumers. It has been shown that providing a breakdown of consumption helps users curtail their usage
typically by 9-20%. Without installing a meter on every appliance, how can an appliance-wise breakdown
be inferred from a single whole house electricity measurement that is provided, say, by a smart meter? This
problem is called energy disaggregation or non-intrusive load monitoring (NILM), and in light of
sustainability has recently attracted a lot of attention from data mining researchers and practitioners.
We proposed an unsupervised approach to energy disaggregation based on a factorial hidden Markov model (FHMM)
that uses low frequency aggregate measurements from a smart meter [SDM 2011]. We proposed FHMM variants that
better capture the probability distributions of appliance ON durations, and that allow additional contextual
features such as hour of day, day of week, and input from other sensors to be incorporated into the model.
We were the first to use a FHMM based approach, which has subsequently been used by several researchers.
In [AAAI 2013], we propose a motif-based approach to energy disaggregation for residential and commercial buildings.
This paper received the best student paper award at AAAI 2013 computational sustainability track.
|
|
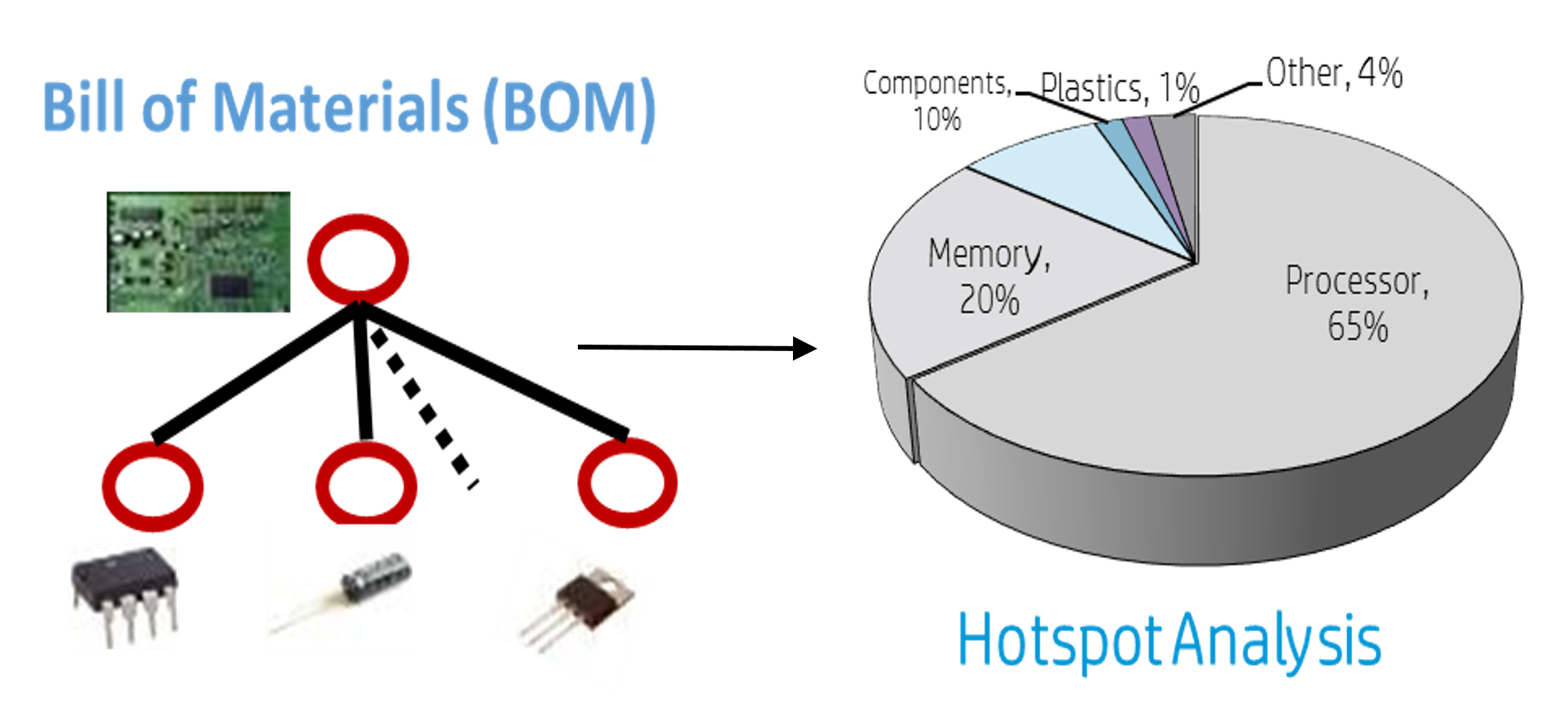
Auto Life Cycle Assessment:
Lifecycle assessment is a widely used method to estimate the
environmental impact, such as greenhouse gas emissions and toxicity,
of a product (e.g., server, handheld). However, it is a manual and
laborious process. We propose several methods to automate this
process and reduce the cost and time associated with environmental
assessments. The data set consists of the product's bill of
materials, and a commercially available database of environmental
impacts of commonly used components. The environmental impacts
database is essentially a matrix, and we use collaborative filtering
techniques to impute missing data; we use a series of clustering,
classification methods on the bill of materials to transform it to the
impact factor space; determine the component tree in the impact factor
space and the top contributors of a particular environmental impact;
and finally, use disparate clustering to suggest alternative
components for more sustainable design.
[ACM TIST 2014] [ICDM 2013] [AAAI 2011] [IEEE Computer 2011] [IEEE ISSST 2011] |
|
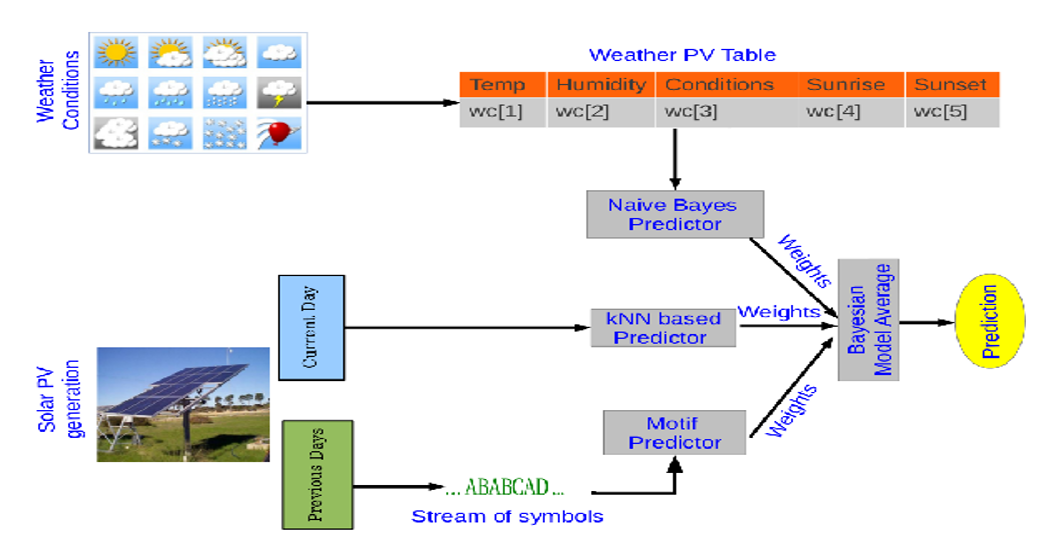
Photo-Voltaic Power Generation Prediction:
Local and distributed power generation is increasingly
reliant on renewable power sources, e.g., solar (photovoltaic
or PV) and wind energy. The integration of
such sources into the power grid is challenging, however,
due to their variable and intermittent energy output.
To effectively use them on a large scale, it is essential
to be able to predict power generation at a fine-grained
level. In this work, we propose a novel Bayesian ensemble
methodology involving three diverse predictors. Each
predictor estimates mixing coefficients for integrating
PV generation output profiles but captures fundamentally
different characteristics. Two of them employ classical
parameterized (naive Bayes) and non-parametric
(nearest neighbor) methods to model the relationship
between weather forecasts and PV output. The third predictor
captures the sequentiality implicit in PV generation
and uses motifs mined from historical data to estimate
the most likely mixture weights using a stream
prediction methodology. We demonstrate the success
and superiority of our methods on real PV data from
two locations that exhibit diverse weather conditions.
Predictions from our model can be harnessed to optimize
scheduling of delay tolerant workloads, e.g., in a
data center.
|
|
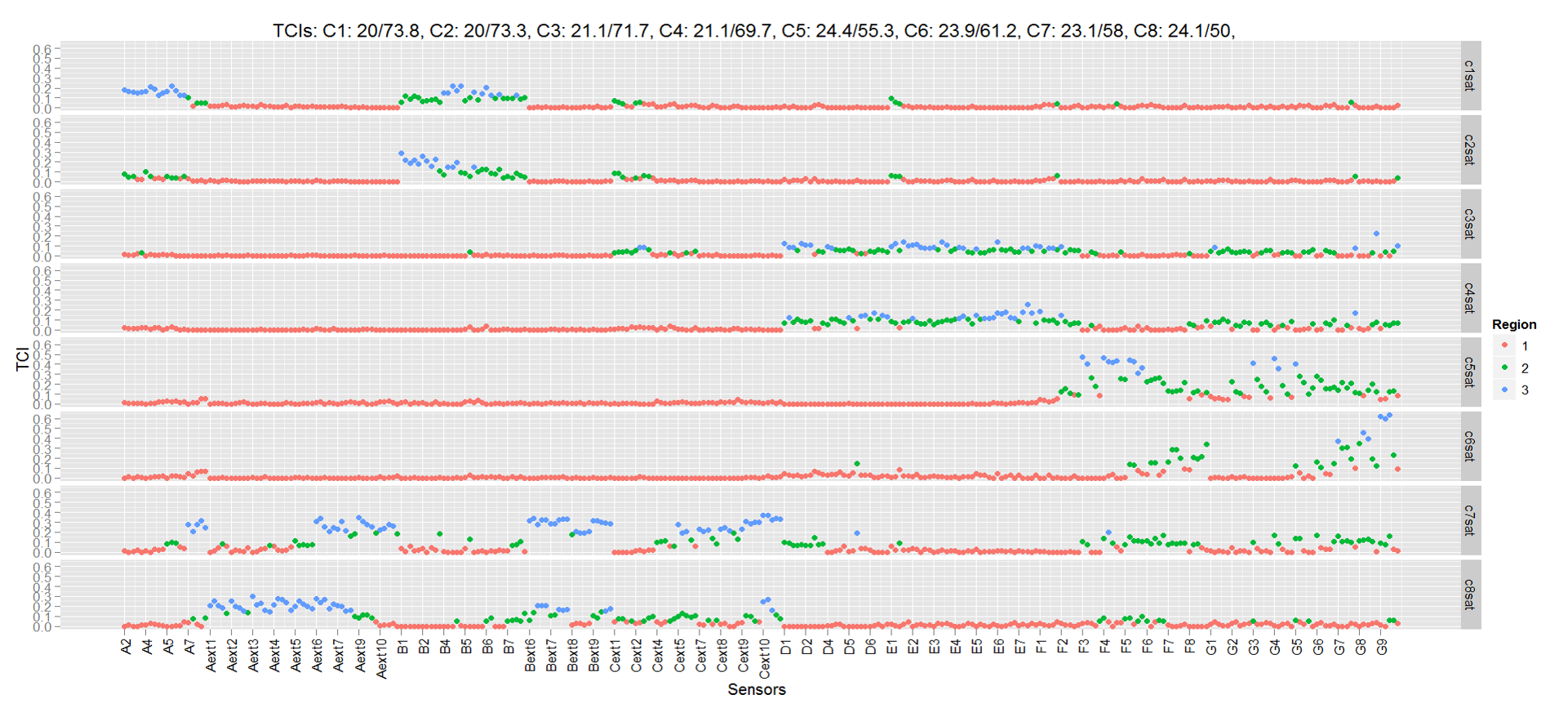
Auto Thermal Correlation Index:
In order to better manage the cooling infrastructure in a
data center with multiple computer room air conditioning
(CRAC) units, the relationship between CRAC settings and
temperature at various locations in the data center needs to be
accurately and reliably determined. Usually this is done via a
commissioning process which is both time consuming and
disruptive. In this paper, we describe a machine learning based
technique to model rack inlet temperature sensors in a data
center as a function of CRAC settings. These models can then
be used to automatically estimate thermal correlation indices
(TCI) at any particular CRAC settings. We have implemented
a prototype of our methodology in a real data center with eight
CRACs and several hundred sensors. The temperature sensor
models developed have high accuracy (mean RMSE error is
0.2 C). The results are validated using manual
commissioning, demonstrating the effectiveness of our
techniques in estimating TCI and in determining thermal
zones or regions of influence of the CRACs.
|
|
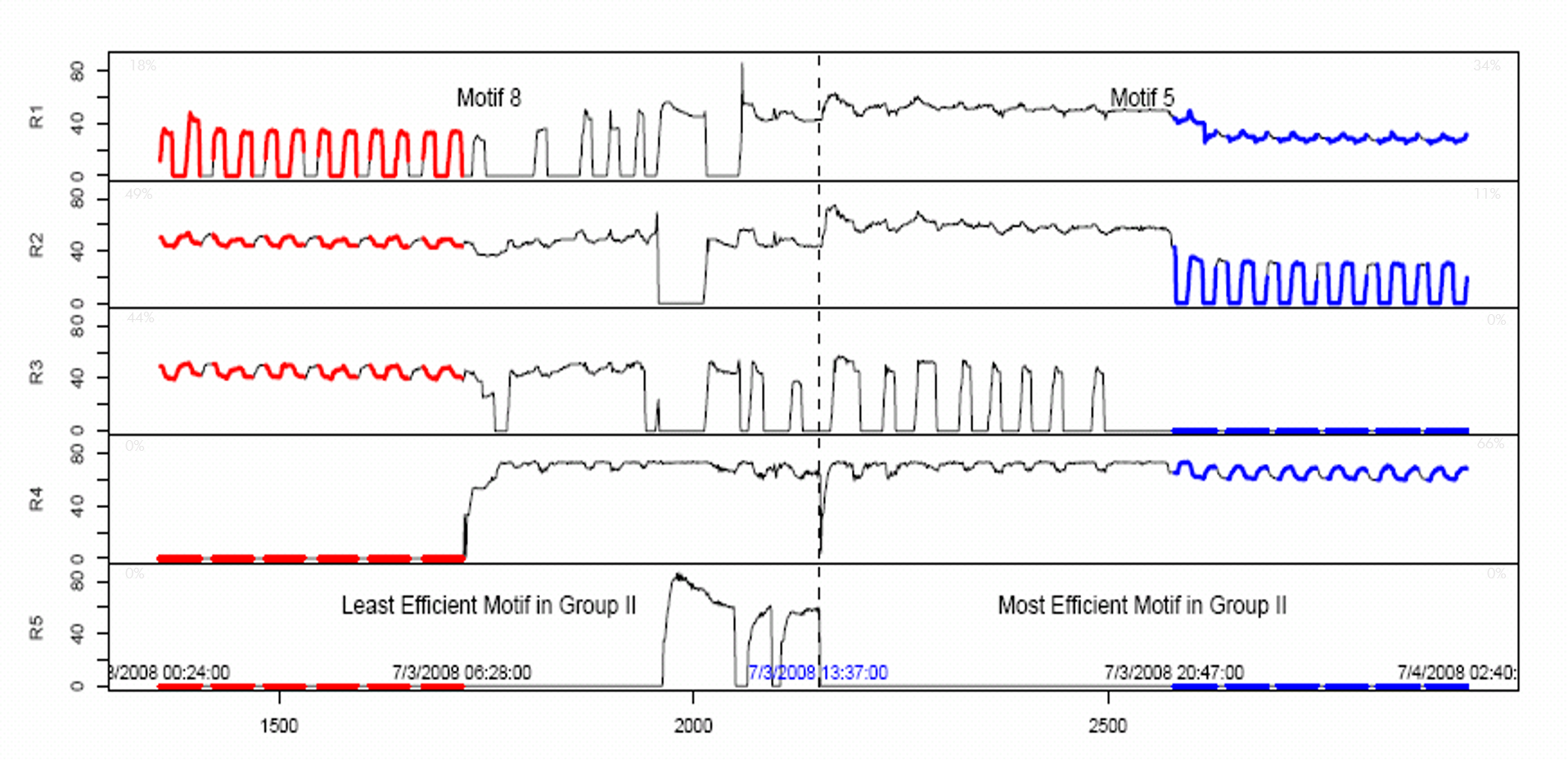
Data Center Chiller Temporal Data Mining:
Practically
every large IT organization hosts data centers-a mix of
computing elements, storage systems, networking, power, and
cooling infrastructure—operated either in-house or outsourced
to major vendors. A significant element of modern data centers
is their cooling infrastructure, whose efficient and
sustainable operation is a key ingredient to the "always-on"
capability of data centers. In this work, we designed and
implemented CAMAS (Chiller Advisory and MAnagement
System), a temporal data mining solution to mine and manage
chiller installations. CAMAS embodies a set of algorithms for
processing multivariate time-series data and characterizes
sustainability measures of the patterns mined. We demonstrate
three key ingredients of CAMAS—motif mining, association
analysis, and dynamic Bayesian network inference-that help
bridge the gap between low-level, raw, sensor streams, and the
high-level operating regions and features needed for an
operator to efficiently manage the data center. The
effectiveness of CAMAS is demonstrated by its application to a
real-life production data center.
|